 NextGen
NextGen



VeReMi NextGen is a dataset for evaluating Misbehavior Detection Systems (MDSs) in Vehicular Ad hoc Networks (VANETs). It provides simulated V2X message logs with ground-truth labels and a broad set of data manipulation attacks. Compared to previous VeReMi datasets, VeReMi NextGen introduces more realistic traffic scenarios, urban and highway environments, multiple driver profiles, sensor error models, predefined training/validation/test sets, and a broader range of attack types. VeReMi NextGen is part of an accpeted paper, submitted to the Vehicular Networking Conference (VNC) 2026.
This website provides a brief overview of the VeReMi NextGen dataset. For more detailed documentation, please refer to the documentation section of our GitHub repository.
Download
The code for reproducing the dataset, including a Docker container, is available in a GitHub repository. The VeReMi NextGen dataset itself is provided on Zenodo. The corresponding links are listed below:
Cite This Work
If you are using our dataset, please use the following citation:
@inproceedings{Hermann2026vereminextgen,
author = {Hermann, Artur and Remmers, Jan-Niklas and Eisermann, Dennis and Erb, Benjamin and Kargl, Frank},
title = {VeReMi {NextGen}: A {Dataset} for {Evaluating} {Misbehavior} {Detection} {Systems} in {VANETs}},
booktitle = {2026 {IEEE} {Vehicular} {Networking} {Conference} ({VNC})},
date = {2026-06},
location = {Montreal, Canada}
}
Overview
VeReMi NextGen is a simulated dataset which stores the messages received by each simulated vehicle. The dataset targets the evaluation of Misbehavior Detection Systems, which aim to detect incorrect data in authentic V2X messages. VeReMi NextGen consists of:
- urban and highway scenarios,
- low- and high-density traffic conditions,
- three driver profiles,
- sensor error models,
- pseudonym changes,
- 15 attack types,
- ground-truth labels,
- predefined training, validation, and test sets,
- a publicly available dataset generator.
VeReMi NextGen addresses several limitations of previous datasets such as VeReMi and VeReMi Extension.
| Feature | VeReMi | VeReMi Extension | VeReMi NextGen |
|---|---|---|---|
| Up-to-date traffic scenario | ✗ | ✗ | ✓ |
| Multiple driver profiles | ✗ | ✗ | ✓ |
| Multi-attribute attacks | ✗ | ✓ | ✓ |
| Urban and highway scenarios | ✗ | ✗ | ✓ |
| Sensor error models | ✗ | ✓ | ✓ |
| Received Signal Strength Indicator | ✓ | ✗ | ✗ |
| Ground-truth labels | ✓ | ✗ | ✓ |
| Training/validation/test sets | ✗ | ✗ | ✓ |
| Extensible design | ✗ | ✗ | ✓ |
| Support for future VRU integration | ✗ | ✗ | ✓ |
Simulation Setup
It was generated using MOSAIC (Version 25.0), SUMO (Version 1.22.0), and OMNeT++ (Version 6.1). It was generated using the InTAS traffic scenario. InTAS represents the city of Ingolstadt and provides realistic traffic dynamics, different road types, public transport, traffic lights, and support for Vulnerable Road Users.
The dataset includes four scenario types:
| Scenario | Environment | Density |
|---|---|---|
| Urban 2 AM | Urban | Low density |
| Urban 7 AM | Urban | High density |
| Highway 2 AM | Highway | Low density |
| Highway 7 AM | Highway | High density |
Separate geographic areas are used for training/validation and test sets to avoid spatial overlap between model training and evaluation. The used geographic areas are shown in the figure below and have in total 10.2 km²:
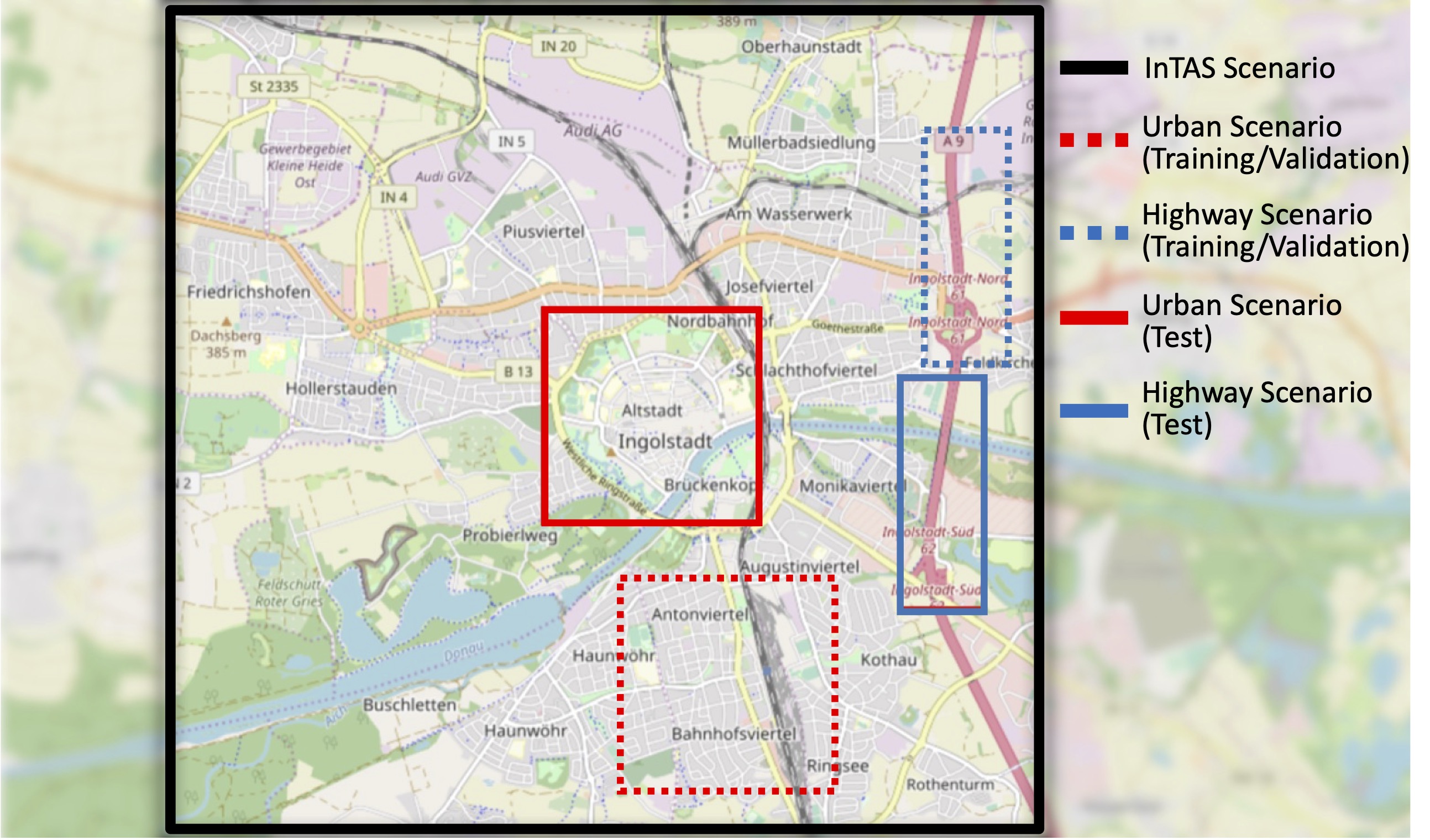
Figure 1: Geographic areas used for the training/validation and test sets in the InTAS scenario.
Dataset Structure
VeReMi NextGen is organized into training, validation, and test sets. Each set contains urban and highway scenarios with low and high vehicle densities. The complete dataset consists of 180 subsets:
- 15 attack subsets,
- 4 scenarios,
- 3 dataset splits: training, validation, and test.
Each subset is organized as a directory containing one JSON file per receiving vehicle. Each file contains all messages received by that vehicle during the simulation. The dataset provides fixed training, validation, and test sets to support reproducible evaluation of machine-learning-based MDSs.
| Scenario | Training duration | Validation duration | Test duration |
|---|---|---|---|
| Urban 2 AM | 9000 s | 1800 s | 7200 s |
| Urban 7 AM | 375 s | 75 s | 300 s |
| Highway 2 AM | 9000 s | 1800 s | 7200 s |
| Highway 7 AM | 375 s | 75 s | 300 s |
Attack Types
VeReMi NextGen includes 15 attack types affecting different message attributes.
| Category | Attack types |
|---|---|
| Time-related | Time Delay Attack |
| Position-related | Constant Position Offset, Random Position Offset, Position Mirroring |
| Speed-related | Constant Speed Offset, Random Speed Offset, Zero Speed Report, Sudden Constant Speed |
| Heading-related | Reversed Heading |
| Acceleration-related | Feigned Braking, Acceleration Multiplication |
| Multi-parameter | Sudden Stop, DoS Attack, Traffic Congestion Sybil, Data Replay |
Six of these attacks were newly designed for VeReMi NextGen. The attacks cover a broader range of message attributes than previous datasets, including heading and acceleration.
The configured attacker density is 20%, meaning that 20% of the vehicles act as attackers. Each message contains an attacker field. A value of 1 indicates that the message contains a significant deviation in at least one attribute, while a value of 0 indicates a legitimate message or a deviation below the defined significance threshold.
Reproducing and Extending the Dataset
VeReMi NextGen was generated in two main steps:
-
Simulation Execution
The V2X simulation is executed using Eclipse MOSAIC and the InTAS scenario. All received CAMs are collected to create the Baseline dataset. -
Post-Processing
Attacks are integrated into the Baseline dataset. This avoids rerunning expensive simulations for every attack and enables consistent attack generation across all receivers.
We provide a Docker container to create the Baseline dataset, as well as scripts for conducting the post-processing. This enables the reproduction of VeReMi NextGen and supports future extensions of the dataset, such as additional attacks, attributes, scenarios, or entities.
VeReMi NextGen Highlights
| Advantage | Description |
|---|---|
| More realistic traffic scenario | Uses InTAS instead of LuST, providing more complex road layouts and more realistic traffic dynamics |
| Urban and highway coverage | Includes both urban and highway scenarios with low and high vehicle densities |
| Heterogeneous driver behavior | Introduces normal, cautious, and aggressive driver profiles |
| Broader attack diversity | Provides 15 attack types affecting a wider range of message attributes |
| New attack types | Includes six newly introduced attacks, such as position mirroring, zero speed report, reversed heading, feigned braking, and acceleration multiplication |
| ML-ready structure | Provides predefined training, validation, and test sets |
| Easier evaluation | Includes ground-truth labels directly in each message |
| Extensible design | Provides a public dataset generator for adding new attacks, attributes, or entities |
| Future VRU support | Based on InTAS, which supports Vulnerable Road User simulation and enables future dataset extensions |
| More challenging benchmark | Evaluation results show that attacks in VeReMi NextGen are harder to detect than in VeReMi Extension |
Acknowledgement
The dataset was primarily put together by Artur Hermann at the Institute of Distributed Systems, Ulm University.
This work was partially funded by the HORIZON CONNECT project under EU grant agreement no. 101069688 and the ConnRAD project under grant agreement no. 16KISR036.